策略训练结果¶
双环境验证解读¶
在使用REVIVE SDK进行任务学习的过程中,默认情况下,REVIVE会将数据集进行切分,并分为训练数据集以及验证数据集(参考 数据准备)。
并在这两个数据集上分别构建虚拟环境,并命名为 trainEnv 和 valEnv。
在随后的策略模型学习过程中,REVIVE会在 trainEnv 和 valEnv 两个环境以及对应的数据集 trainData 和 valData 中分别进行策略模型的训练,
训练出各自的策略模型 trainPolicy 和 valPolicy。
在训练过程中,REVIVE SDK会在训练结束后,依据用户设定的 奖励函数 ,
对 trainPolicy 在 trainEnv 和 valEnv``上,以及 ``valPolicy 在 trainEnv 和 valEnv 上所获得的平均单步奖励进行记录,
并生成双重环境验证图。该验证图保存在 logs/<run_id>/policy_train(tune/../)/double_validation.png 当中。
双环境验证是一种用于评估策略模型性能的方法。它涉及将训练和测试环境定义为两个不同的环境。 在训练期间,智能体使用一个环境进行学习;而在测试期间,它必须在另一个环境中进行操作,该环境可能与训练环境略有不同。 通过这种方式,双重环境验证可以检测出策略模型过度拟合特定的环境。 如果训练环境和测试环境非常相似,那么模型可能会在测试环境中表现良好。 但如果测试环境与训练环境有明显区别,则模型可能无法泛化到新环境中。 因此,双环境验证可以帮助用户确定评估策略模型的实际效果,并检查它们是否具有适应不同环境的能力。
我们 使用REVIVE SDK控制摆杆的运动 任务为例对双重环境验证图进行说明:
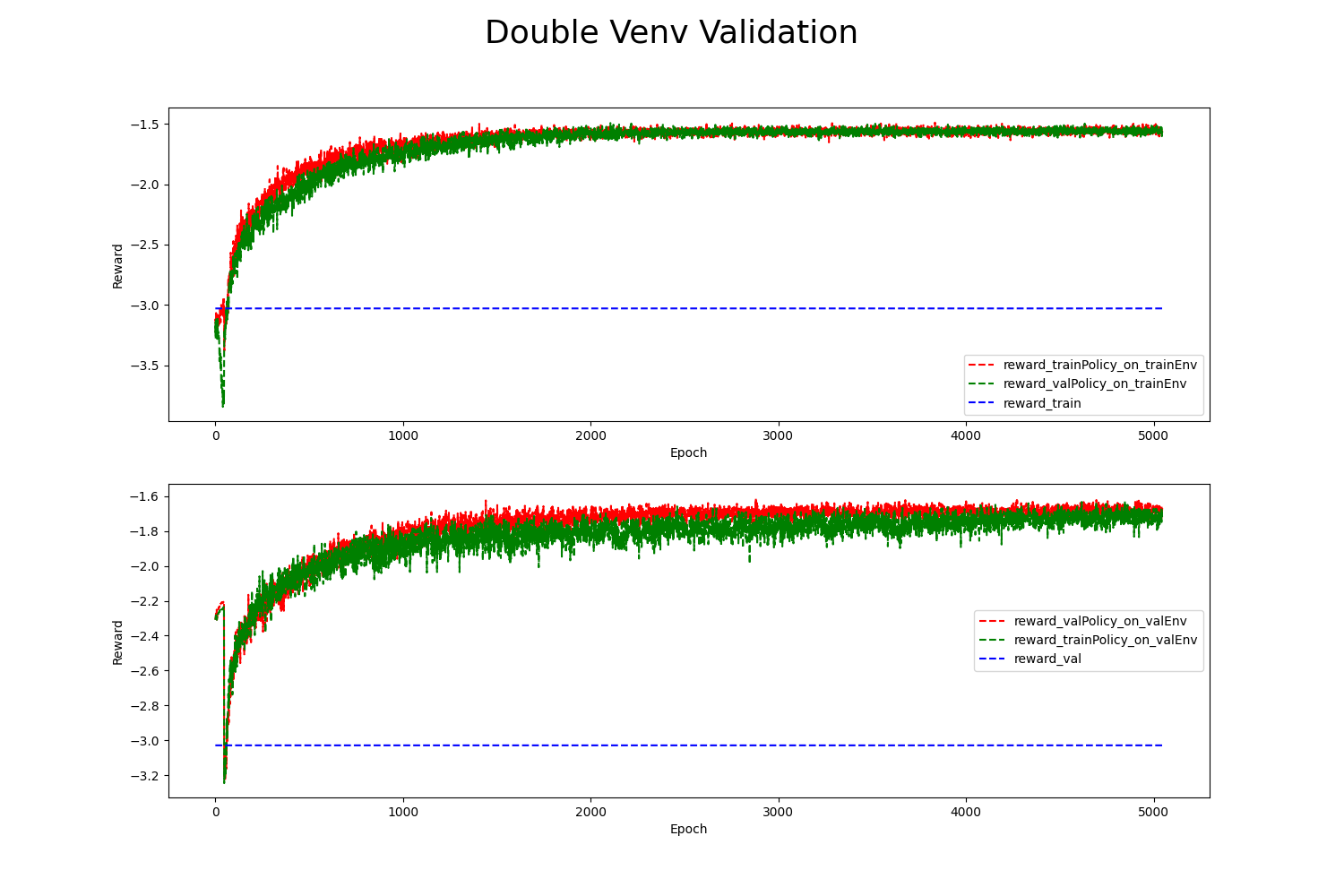
图中:
reward_val/reward_train: 蓝色虚线是REVIVE SDK用训练/验证数据在用户设定的 奖励函数 中计算得到的单步奖励平均值。
reward_*Policy_on_*Env: 红/绿虚线是在
*Env虚拟环境中使用*Policy策略所记录的单步奖励平均值。上下两张图分别记录了两个策略在
trainEnv和valEnv中的结果。
从图中我们可以看到:
红绿两条线都高于蓝色虚线。这意味着在两个环境中,两种策略得到的奖励数值都高于了历史数据集中的奖励数值。
上图中的红线(
reward_trainPolicy_on_trainEnv)和下图中的绿线(reward_trainPolicy_on_valEnv)随着训练轮次的增加有相似的走势。 我们也能从上图中的绿线和下图中的红线发现同样的结果。这表明,训练的trainPolicy并没有在其对应训练的虚拟环境trainEnv上过拟合。 得到的策略模型可以泛化到其他的环境中。由于
trainPolicy能够在valEnv中有良好的表现,我们可以认为trainEnv和valEnv有一定的相似性。 这表明在虚拟环境训练时的超参数设置能够在划分的训练数据和验证数据上得到相近且有价值的环境模型。
下面的图显示了一个失败的双环境验证结果。
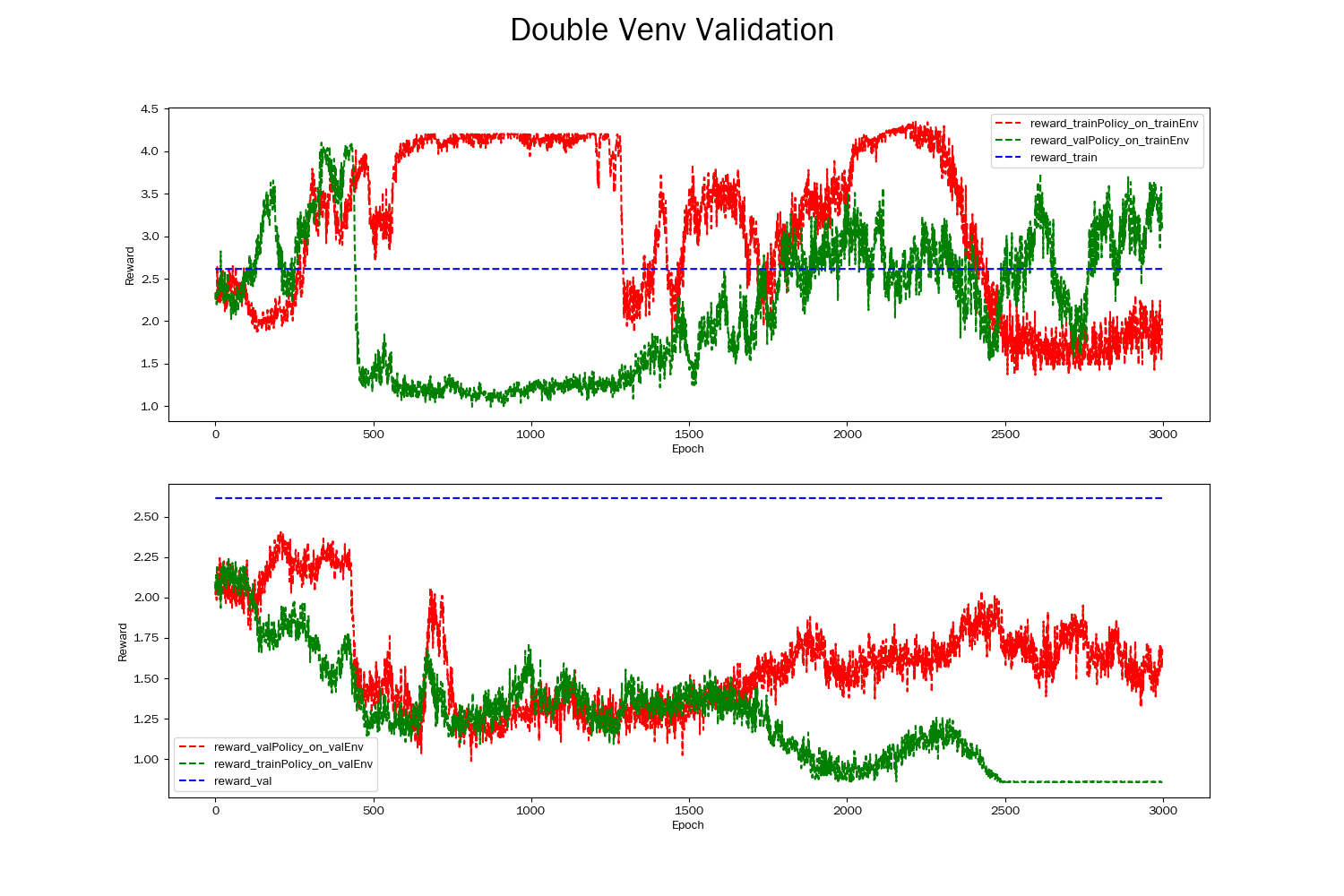
从图中我们发现,同一策略并没有在两个环境中有相似的表现。另外,两种策略表现都没有稳定地收敛并高于蓝色虚线之上。
一般情况下双环境验证不通过的原因有以下几点:
训练环境与测试环境不一致。如果训练集和测试集中一些维度的数据分布差异较大,那么训练集得到的
trainPolicy在valEnv的表现可能会大打折扣。过度拟合。当
trainPolicy在trainEnv中过多地学习了噪声或特定环境下的规律时,就会导致其在valEnv下表现不佳。 如果trainPolicy复杂度过高,它可能会过度拟合trainData,导致在valEnv中的性能下降。样本数量不足。如果训练数据太少,模型可能无法充分学习环境中的规律,从而导致学习得到的虚拟环境并不能很好的模拟真实环境。
超参数选择不当。例如,学习率过高或过低、折扣因子选择不当等,都可能导致模型在测试环境中表现不佳。
环境动态变化。如果环境的动态性较大,比如说在训练期间环境发生了变化,那么模型在测试环境中的表现也可能会出现差异。
最后需要明确,双环境验证方法是评估策略模型性能的众多方法之一,也是判断策略模型泛化性能的重要指标。 但这并不意味着如果双环境验证通过,那么策略模型在真正的实际环境中就能够有理想的效果。 同时也并不代表学习得到的虚拟环境就能够完美地复刻真实环境。