虚拟环境训练结果¶
虚拟环境度量指标解读¶
在使用 REVIVE SDK 学习虚拟环境之前,我们可以通过配置 config.json 文件中的 venv_metric 来度量训练过程中虚拟环境与历史真实数据之间的差异度。
venv_metric 可以配置以下四种方法:
nll:负对数似然损失函数(Negative Log Likelihood),用来衡量模型预测类别的不确定性和实际类别之间的差距。mae:平均绝对误差(Mean Absolute Error),衡量虚拟环境模型预测值与真实历史数据之间的绝对差异。mse:均方误差(Mean Squared Error),衡量虚拟环境模型预测值与真实值之间的平方差异。wdist:Wasserstein距离(Wasserstein Distance),衡量两个概率分布之间的距离,即将一个分布变成另一个分布所需的最小成本。
这些量都是用来衡量REVIVE在虚拟环境进行自回归调用所记录的数据与真实环境得到的历史数据进行对比的结果。 具体来讲,REVIVE使用训练数据集得到的虚拟环境模型来与验证数据集的历史数据进行对比,这样可以从泛化性的角度出发来度量虚拟环境模型。
在默认情况下, venv_metric 是设定为 mae 。
用户可以通过 Tensorboard 来查看这一指标的变化,在终端输入以下命令:
tensorboard --logdir .../logs/<run_id>
我们以 使用REVIVE SDK控制摆杆的运动 任务为例,来查看 venv_metric 的指标随训练过程的变化情况。
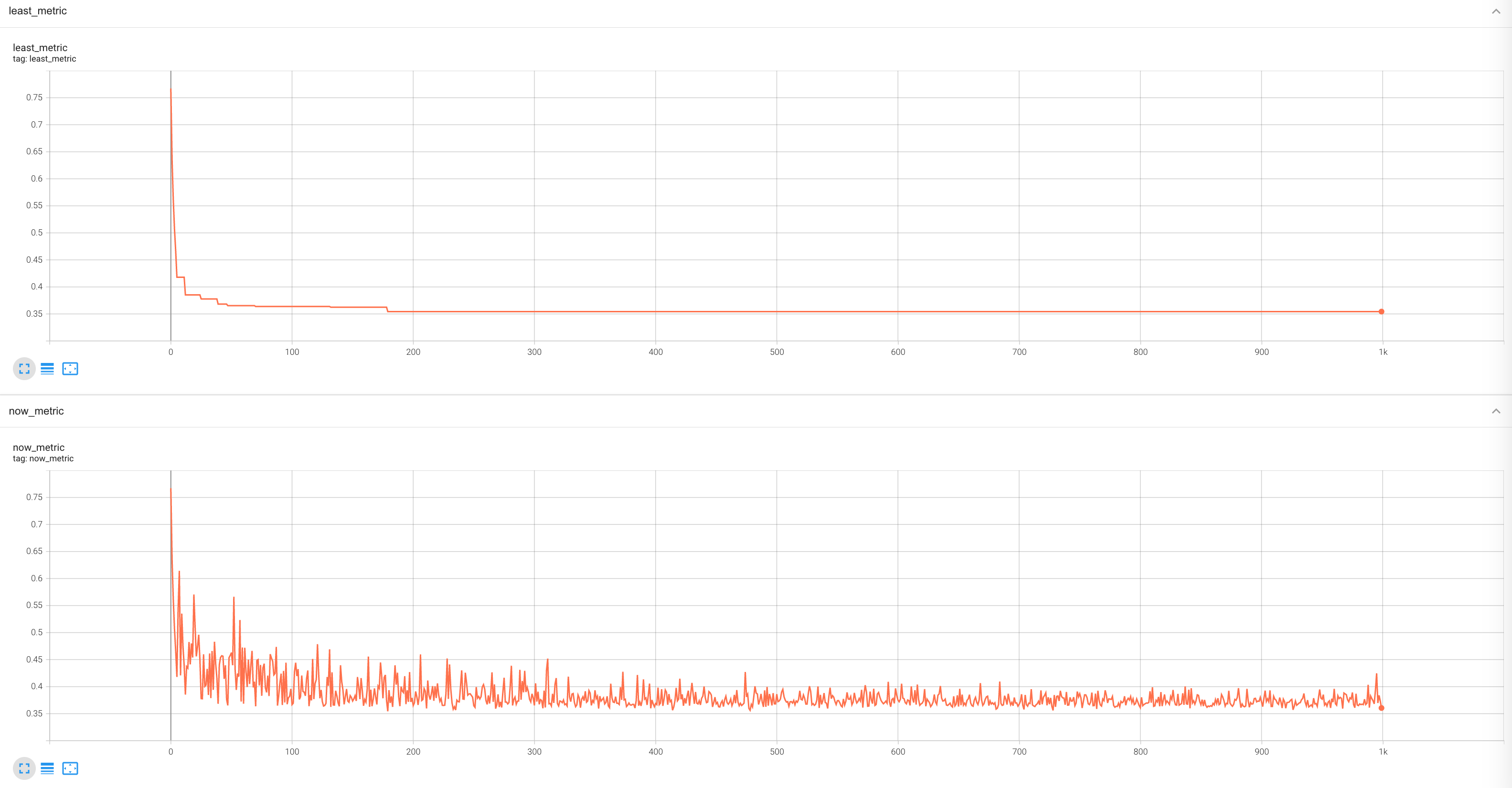
如上图所示,在 tensorboard 记录的众多指标中, now_metric 和 least_metric 是用来记录 venv_metric 。其中次任务中, venv_metric 设定为 mae。
now_metric记录了每轮训练epoch下mae的数值。least_metric记录当前训练轮次之前的所有轮次中最小的now_metric数值,因此可以被视为now_metric图中曲线轮廓的下界。当
least_metric变得更低时,REVIVE 则会保存或替换保存虚拟环境模型。
我们可以看到,当训练轮次达到 200 轮之后, least_metric 更新了更低的数值,此时REVIVE保存当前轮次的网络模型。
由于 least_metric 没有进一步变小,所以REVIVE不会保存新的模型。
此时我们就可以手动停止虚拟环境模型的训练,并转到之后的策略训练中。
rollout图解读¶
rollout图是指在按照特定策略运行机器人或智能体时,显示其在不同时间步骤上所采取的行动和获得的奖励的图表。 这个图表可以用来评估策略在特定环境下是否有效,以及确定需要改进的地方。 在rollout图中,横轴代表时间步骤,纵轴表示机器人或智能体的状态和动作变化情况。
通过观察rollout图,我们可以了解机器人或智能体在运行过程中的行为以及获得的奖励。 如果发现机器人或智能体在某些时间步骤上表现不佳或者某些行动导致负面的结果,我们就可以考虑调整策略,以期望在未来的运行中获得更好的结果。 rollout图可以帮助我们诊断评估虚拟环境和真实数据之间的差距。
在REVIVE SDK学习虚拟环境中后,REVIVE会将我们使用的训练数据(即从真实环境中采集到的历史数据集),在决策流的规定逻辑下进行重新回放。 而这些历史数据都是从真实的环境场景中采集得到的,所以这样的对比可以间接辅助用户判断学习到的虚拟环境模型与真实场景的差距或异同。
Tip
用户也可以根据 使用训练完成的模型 的介绍,加载虚拟环境模型来绘制满足定制化需求的rollout图。
这里我们以Pendulum为例来进一步解释REVIVE保存下来的rollout图。
metadata:
graph:
actions:
- states
next_states:
- states
- actions
columns:
- obs_states_0:
dim: states
type: continuous
- obs_states_1:
dim: states
type: continuous
- obs_states_2:
dim: states
type: continuous
- action:
dim: actions
type: continuous
在倒立摆任务中,我们建立了上述的决策流图。其中 states 具有三维数据, actions 具有一维数据,
更多详细的数据说明可以参考 使用REVIVE SDK控制摆杆的运动 中的内容。

如以上动画所示,左侧为REVIVE虚拟环境中的摆杆运动情况,右侧为真实环境中历史数据的运动情况。 我们可以将REVIVE保存的rollout图理解为:以个数据的维度为最小单元,与真实环境采样得到的历史数据进行对比的二维折线图。
REVIVE在绘制rollout图的过程中遵循了以下步骤:
REVIVE会从数据集中随机采集10条轨迹,进行虚拟环境模型和真实历史数据的对比。(REVIVE会根据训练数据集的最短轨迹长度进行裁剪,使得这一批随机采集的10条轨迹长度完全相同)。
REVIVE会根据决策流图
graph中节点的名称来循环调用数据(参考 决策流图和数组数据 )。 在绘制rollout图时,采用此自回归方法完成。因此rollout结果是完全基于虚拟环境模型进行绘制的。在当前示例中,REVIVE会读取
graph中的节点信息,并对两个节点actions和next_states,以及输入节点states进行rollout图的绘制。 因此,在rollout_images目录下,会按照这三个节点的名称来保存对应的rollout图。

以上是 使用REVIVE SDK控制摆杆的运动 任务中 states 数据的其中一副 rollout 图示例。
History Expert Data 代表的红色虚线为训练虚拟环境时使用的历史数据。
Policy Expert Data 代表的红色虚线为训练虚拟环境时使用的历史数据。
由于 states 有三维,因此在图中分别按照维度名称展示了三个维度的rollout数据,并使用决策流中 columns 定义的名称来命名纵轴。
横轴表示rollout步骤数,共计200步。200步也是数据集中,每条轨迹的长度。
从图中可以看出,在小于100步时,虚拟环境模型的自回归结果与真实数据的误差较小。
但在超过100步之后,虚拟环境模型虽然能够生成与数据相似的数值变化趋势,但仍会与真实数据产生较大的差异。
所以基于此虚拟环境进行策略模型训练时,我们就不应该设置 policy_horizon 大于100的数值。
综上所述,查阅rollout图是我们最直观判断虚拟环境模型与真实环境(历史数据)差别的方法。
通过该方法,我们可以用最短的时间对虚拟环境模型的误差程度进行粗略的判断,
也可据此对后续策略模型学习的 policy_horizon 步长设定提供依据。
虽然虚拟环境模型无法以100%准确度复刻真实环境,但存在一定误差并不意味着REVIVE无法借此进行策略优化。