响应曲线¶
什么是响应曲线¶
响应曲线是描述系统或过程中输入与输出关系的图形表现。 通常在二维图上绘制,输入变量在横轴 (x 轴) 上,输出变量在纵轴 (y 轴) 上。输入变量可以是任何可测量的参数,例如频率、时间、电压或温度等。 输出变量可以是任何受输入影响的参数,例如幅度、相位、功率或电阻等。
在许多领域,响应曲线被用于分析和优化系统或过程的性能。 例如,在音频工程中,扬声器的频率响应曲线显示了其对不同频率声音的输出水平变化。 通过分析这条曲线,工程师可以确定扬声器的频率范围、灵敏度和失真特性,并根据需要进行设计调整。 同样,在电子学中,响应曲线可用于分析电路或设备的性能:例如,晶体管的电流电压 (I-V) 曲线显示了其输出电流随输入电压变化的情况。 通过分析这条曲线,工程师可以确定晶体管的工作区域、增益和线性度,并为不同应用优化其性能。 响应曲线也可用于比较不同系统或过程。 例如,对比不同音频扬声器或电子设备的响应曲线,可以帮助工程师选择最适合特定应用的选项。 总之,响应曲线是分析和优化许多领域中系统和过程性能的重要工具。 通过提供输入和输出变量之间关系的图形表现,它们帮助工程师和科学家了解系统或过程的特性,并做出有根据的决策来改进它们。
用 REVIVE SDK 绘制响应曲线¶
REVIVE SDK 也提供了绘制响应曲线的功能。有以下两种方式调用响应曲线的绘制:
1. 在 config.json 文件中 base_config 域下配置¶
default 中 true 即为开启响应曲线绘制, false 关闭。
{
"base_config": [
...
{
"name": "plt_response_curve",
"abbreviation": "prc",
"description": "Whether to plot response curve at the end of venv training.",
"type": "bool",
"default": true
},
...
],
...
}
}
这样 REVIVE 会在环境训练结束时自动绘制双环境(训练环境与验证环境)的响应曲线,
路径位于 logs/<run_id>/venv_train/response_curve。
以冰箱温控为例,生成的文件目录结构如下:
response_curve
|-- action
| `-- action_on_temperature.png
`-- next_temperature
|-- next_temperature_on_action.png
|-- next_temperature_on_door_open.png
`-- next_temperature_on_temperature.png
该目录下每个文件夹对应决策流图中一个网络节点,比如这里 action 与 next_temperature 是网络节点,他们作为输出变量。
每个文件夹中有若干图片,分别代表不同输入对这个输出的响应曲线,比如 action_on_temperature.png 代表 action 对 temperature 的响应曲线。
如下所示:
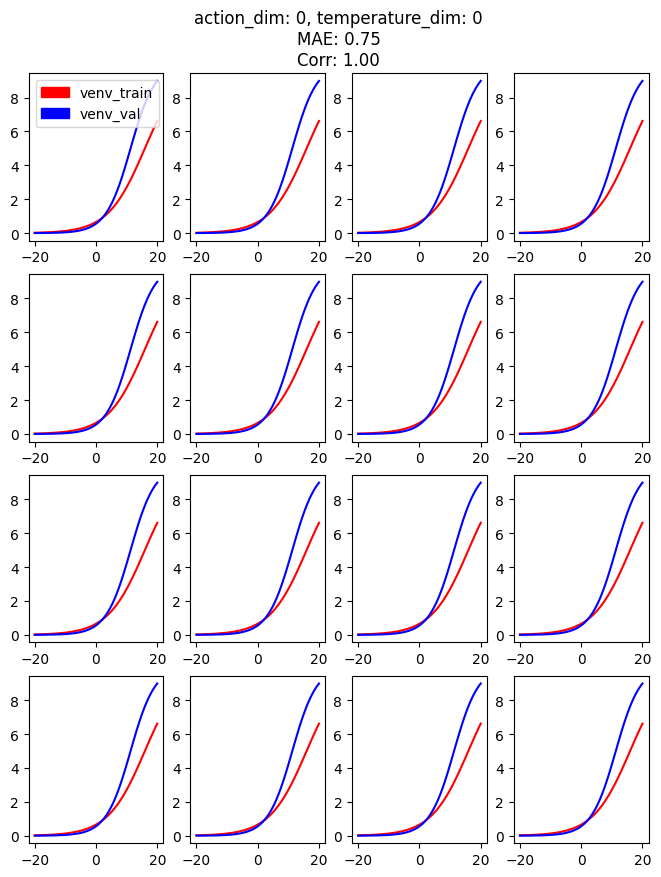
可以看到有 16 幅子图,这是从数据集中随机采样 16 个数据点所绘而成。
x 轴代表了自变量 temperature 的变化范围,y 轴代表因变量 action 的变化趋势。
红线代表训练环境的预测值,蓝线代表验证环境的预测值。
从图中可以看到:随着 temperature 逐渐升高,冰箱电机的功率(action)逐渐增大,使得冰箱内温度稳定在目标温度 -2 度左右。
并且其中训练环境与验证环境的趋势基本一致,表明两个环境的一致性还挺好。
我们还可以计算 2 个环境之间的 MAE 以及 Spearman Correlation 系数,我们可以在每个16宫格的小标题处看到这些信息。
需要说明的是 MAE 以及 Correlation 系数是在 16 个子图中,以及每个 action 上做了平均。
高维数据请看下面的例子:
2. 通过调用 REVIVE SDK 提供的脚本绘制¶
import pickle
from revive.data.dataset import OfflineDataset
from revive.utils.common_utils import load_data, response_curve
if __name__ == "__main__":
dataset_path = "data/halfcheetah-medium-v2.npz" # 替换为对应数据集路径
yaml_path = "data/halfcheetah-medium-v2.yaml" # 替换为对应 yaml 文件路径
dataset = OfflineDataset(dataset_path, yaml_path).data
venv = pickle.load(open("logs/revive/env.pkl", 'rb'), encoding='utf-8') # 换成对应环境的路径
save_path = "./response" # 设置保存路径
response_curve(save_path, venv, dataset)
以 HalfCheetah 为例,生成的文件目录结构如下:
response
|-- action
| `-- action_on_obs.png
|-- delta_x
| |-- delta_x_on_action.png
| `-- delta_x_on_obs.png
`-- next_obs
|-- next_obs_on_action.png
|-- next_obs_on_delta_x.png
`-- next_obs_on_obs.png
比如 next_obs_on_action.png 代表 next_obs 对 action 的响应曲线。
如下所示:
下面我们详细解释 response curve 是如何生成。假定我们的数据有以下形式定义:
obs |
Continuous(17,) |
\(S^i = [s^i_0, s^i_1, ..., s^i_{16}]\) |
action |
Continuous(6,) |
\(A^i = [a^i_0, a^i_1, ..., a^i_5]\) |
next_obs |
Continuous(17,) |
\({NS}^i = [ns^i_0, ns^i_1, ..., ns^i_{16}]\) |
首先,我们从数据集中采样 16 个数据点:\(<S^0, A^0, {NS}^0>, <S^1, A^1, {NS}^1>, ..., <S^{15}, A^{15}, {NS}^{15}>\),
比如宫格 (next_obs_dim: t , action_dim: k) 中有 16 个子图,
它们代表:我们对 \(a^i_k\) 取遍 action 第 k 维的数据范围,也即 [-1, 1] 中取遍每一个值。
同时观察 \(ns^i_t\) 的变化情况。
就是说,在给定 \(S^i\) 的情况下,观察 \(ns^i_t\) 对 \(a^i_k\) 的响应情况。
这里 \(i \in [0, 15], t \in [0, 17], k \in [0, 5]\)。