使用REVIVE SDK控制冰箱温度¶
冰箱温度控制系统介绍¶
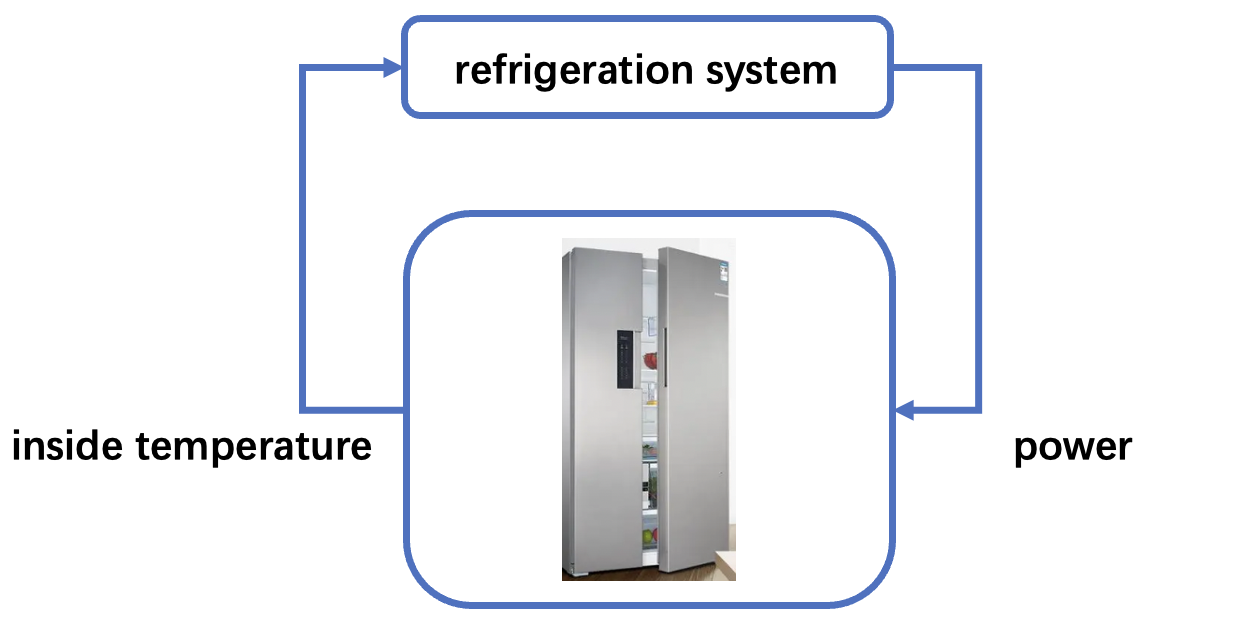
假设我们需要一个温度控制系统来将冰箱的温度控制到理想的目标温度(在下面的示例中设置为-2°C),以便更好地保存食物。 如下图所示,冰箱控制系统通过控制用电功率来调节温度。用电功率越高,制冷效果越强,用电功率越低,制冷效果就越弱。 需要注意的是,由于当前的温度控制系统(PID控制策略)的控制效果并不稳定,而且存在冰箱门不定时被打开的情况, 导致冰箱温度在目标温度附近存在较大的波动,我们希望可以改进当前系统的温度控制策略,改善冰箱的温度控制效果。
历史数据介绍¶
在上述的冰箱温控系统中,我们可以观察诸如冰箱内部的温度、冰箱的当前用电功率,冰箱门的开关状态等数据。
在收集到的历史数据中中,有四列数据分别为 door_open (冰箱门开关状态,1表示打开,0表示关闭), temperature (冰箱内部的温度), action (用电功率)和 next_temperature (冰箱内部下一时刻的温度)。
当前的PID控制策略¶
PID控制是一种常见的温控策略,它基于比例、积分和微分三个方面对温度进行调节。PID控制器通过测量冰箱当前温度与预设温度之间的差异(称为误差), 将这个误差转换成一个输出信号来控制用电功率以调节温度。
任务目标¶
控制策略的任务目标是使冰箱内的温度尽可能接近目标温度(以下示例中为-2°C)。
使用REVIVE SDK训练冰箱温度控制控制策略¶
REVIVE SDK是一个历史数据驱动的工具,根据文档教程部分的描述,在冰箱温控任务上使用REVIVE SDK可以分为以下几步:
收集冰箱温控任务的历史决策数据;
结合业务场景和收集的历史数据构建 决策流图和数组数据,其中决策流图主要描述了业务数据的交互逻辑, 使用
.yaml文件进存储,数组数据存储了决策流图中定义的节点数据,使用.npz或.h5文件进行存储。有了上述的决策流图和数组数据,REVIVE SDK已经可以进行虚拟环境模型的训练。但为了获得更优的控制策略,需要根据任务目标定义 奖励函数 ,奖励函数定义了 策略的优化目标,可以指导控制策略将冰箱内温度更好的控制在理想温度附近。
定义完 决策流图, 训练数据 和 奖励函数 之后,我们就可以 使用REVIVE SDK开始虚拟环境模型训练和策略模型训练。
最后将REVIVE SDK训练的策略模型进行上线测试。
收集历史数据¶
我们首先使用PID策略在冰箱仿真环境中进行控制,获得历史控制数据,在收集到的历史数据中中,有四列数据分别
为 door_open (冰箱门开关状态,1表示打开,0表示关闭), temperature (冰箱内部的温度), action (用电功率)和 next_temperature (冰箱内部下一时刻的温度)。
定义决策流图和准备数据¶
完成历史数据收集后,我们就需要根据冰箱温度控制的业务场景来构建决策流图和数组数据。决策流图准确地定义了数据之间的决策因果关系。
在冰箱温度控制系统中,可以划分四个数据节点,分别是 door_open (冰箱门开关状态), temperature (冰箱内部的温度), action (用电功率)
和 next_temperature (冰箱内部下一时刻的温度)。
根据常识和物理原理,我们可以推断出以下因果关系:
当冰箱门打开时,外部空气会进入冰箱内部,从而导致温度上升。
冰箱内部的温度与下一时刻的温度存在先后关系,并且当前时刻的温度会影响下一时刻的温度。
用电功率的大小与冰箱制冷的效率有关,会会影响下一时刻的温度。
冰箱的温度控制策略只能根据当前的温度进行调控,不能感知到冰箱门的开关状态(外部变量)和下一时刻的温度(未来变量)。
根据上面对冰箱温度控制业务的逻辑描述,可定义如下所示的决策流图:
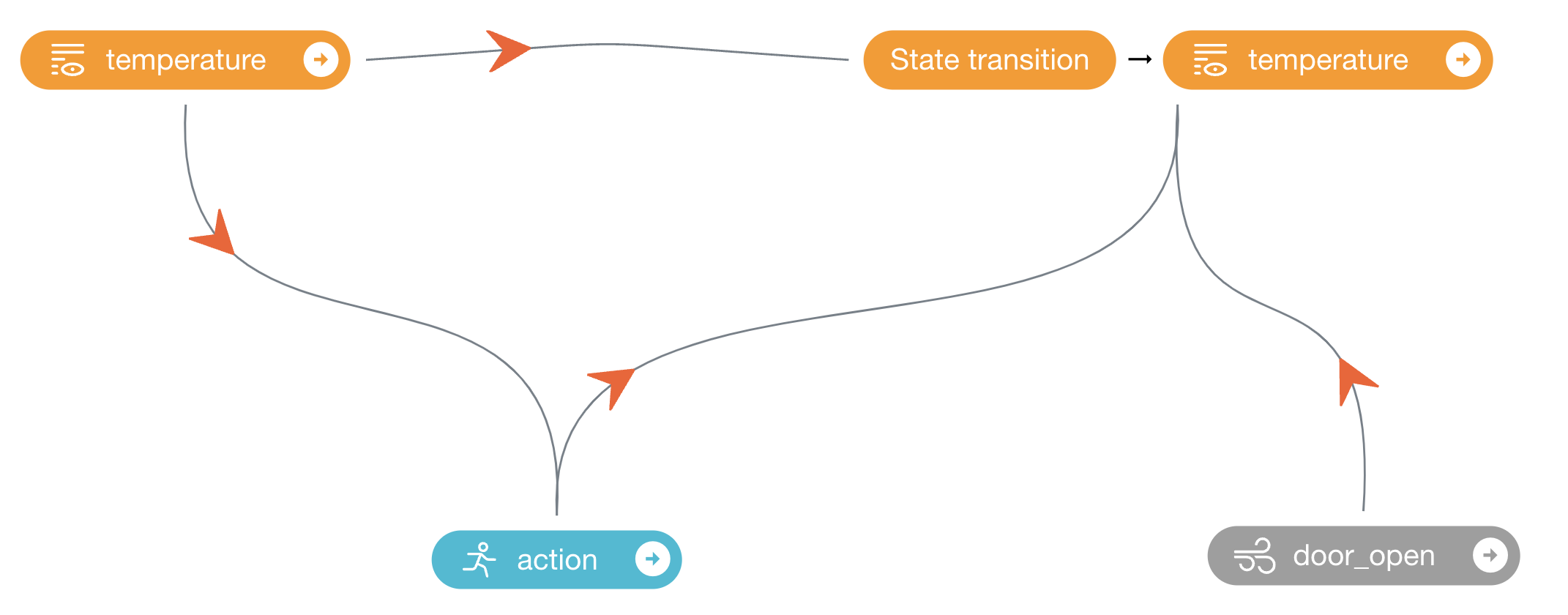
其中 action 节点是策略控制节点,输入是 temperature 节点,表示 action 的值(功率)由当前的温度所决定。
door_open 是一个外部变量,作为 next_temperature 节点的输入,代表其能够影响下一时刻冰箱内温度的变化,
但是不会被图中的其它节点影响。 action , temperature 和 door_open 三个节点共同作为 next_temperature 节点的输入,
表示这三个节点共同影响下一时刻冰箱内温度。上述 .yaml 文件描述的决策流图符合冰箱温度控制系统的场景逻辑。
该决策流图对应于 .yaml 文件如下所示:
metadata:
graph:
action:
- temperature
next_temperature:
- action
- temperature
- door_open
columns:
- obs_temp:
dim: temperature
type: continuous
max: 20
min: -20
- power_action:
dim: action
type: continuous
max: 10
min: 0
- factor_door_state:
dim: door_open
type: continuous
在准备决策流图的过程中我们也将原始的数据转换为 .npz 文件进行存储 。
定义决策流图和准备数据的更多细节描述可以参考 准备数据 章节的文档介绍。
定义奖励函数¶
奖励函数的设计对于学习策略至关重要。一个好的奖励函数应该能够指导策略向着预期的方向进行学习。REVIVE SDK支持支持以python源文件的方式定义奖励函数。
为了获得更好的冰箱制冷策略,我们可以定义一个奖励函数来度量温度控制效果(文件名为 refrigeration_reward.py ),该奖励函数根据当前温度和目标温度之间的差异来计算奖励值,差异越小,奖励值越高。
奖励函数的定义如下:
import torch
from typing import Dict
def get_reward(data : Dict[str, torch.Tensor]) -> torch.Tensor:
'''
data: 包含所有定义在决策流图中的节点数据。
return reward
'''
target_temperature = -2 #代表冰箱的目标问态度
reward_temperature = - torch.abs(data['next_temperature'][...,0:1] - target_temperature)
return reward_temperature
上述奖励函数的目标是将冰箱控制到指定的温度(-2°C)。
定义奖励函数的更多细节描述可以参考 准备数据 章节的文档介绍。
训练一个更好的冰箱温度控制策略¶
REVIVE SDK已经提供了上面所述的数据和奖励函数文件,详情请参考 REVIVE SDK源码库。
完成REVIVE SDK的安装后,可以切换到 examples/task/Refrigerator 目录下,运行下面的Bash命令开启虚拟环境模型训练和策略模型训练。在训练过程中,我们可以随时使用tensorboard打开日志目录以监控训练过程。当REVIVE SDK完成虚拟环境模型训练和策略模型训练后。
我们可以在日志文件夹( logs/<run_id>)下找到保存的模型( .pkl 或 .onnx)。
开始训练的命令如下:
python train.py -df refrigeration.npz -cf refrigeration.yaml -rf refrigeration_reward.py --run_id refrigeration
Note
REVIVE SDK已经提供该示例的数据和代码,支持一键运行。数据和代码可以在 SDK源代码存储库 中找到。
测试训练完成的策略模型¶
最后,我们需要使用我们训练的模型来控制冰箱。下面,我们给出一个使用该模型在冰箱环境上测试的示例。 有关使用经过训练的模型或策略的更多信息,请参阅:使用训练完成的模型。
import os
import pickle
import numpy as np
# 获得模型文件路径
policy_model_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"logs/run_id","policy.pkl")
# 加载模型文件
policy_model = pickle.load(open(policy_model_path, 'rb'), encoding='utf-8')
# 随机生成状态信息
state = {'temperature': np.random.rand(2, 1)}
print("Model input state:", state)
# 用策略模型进行推断
action = policy_model.infer(state)
print("Model output action:", action)
也可以直接使用REVIVE SDK提供的notebook脚本在进行策略的控制效果测试。详情可以参考 refrigerator.ipynb。