Policy Training Results¶
Interpretation of Double Environment Validation¶
During the process of task learning using the REVIVE SDK, by default,
REVIVE splits the dataset into training and validation datasets
(refer to Data Preparation).
It then builds virtual environments for each of these datasets: trainEnv and valEnv.
In the subsequent policy model learning process, REVIVE trains policy models
(trainPolicy and valPolicy) on both trainEnv and valEnv,
as well as their corresponding datasets trainData and valData.
During training, after completion, the REVIVE SDK records the average single-step rewards
obtained by trainPolicy on trainEnv and valEnv, and valPolicy on trainEnv and valEnv,
based on the user-defined reward function.
This information is used to generate the double environment validation graph, which is saved
in logs/<run_id>/policy_train(tune/../)/double_validation.png.
Double environment validation is a method used to evaluate the performance of policy models. It involves defining two separate environments for training and testing. During training, the agent learns using one environment, while during testing, it must operate in another environment, which may differ slightly from the training environment. In this way, double environment validation can detect if a policy model overfits to a specific environment. If the training and testing environments are very similar, the model may perform well in the testing environment. However, if there are significant differences between the testing and training environments, the model may fail to generalize to new environments. Therefore, double environment validation can help users determine the actual effectiveness of evaluating policy models and check if they have the ability to adapt to different environments.
We will use the example of Controlling the Pendulum’s Movement Using REVIVE SDK to illustrate the double environment validation graph.
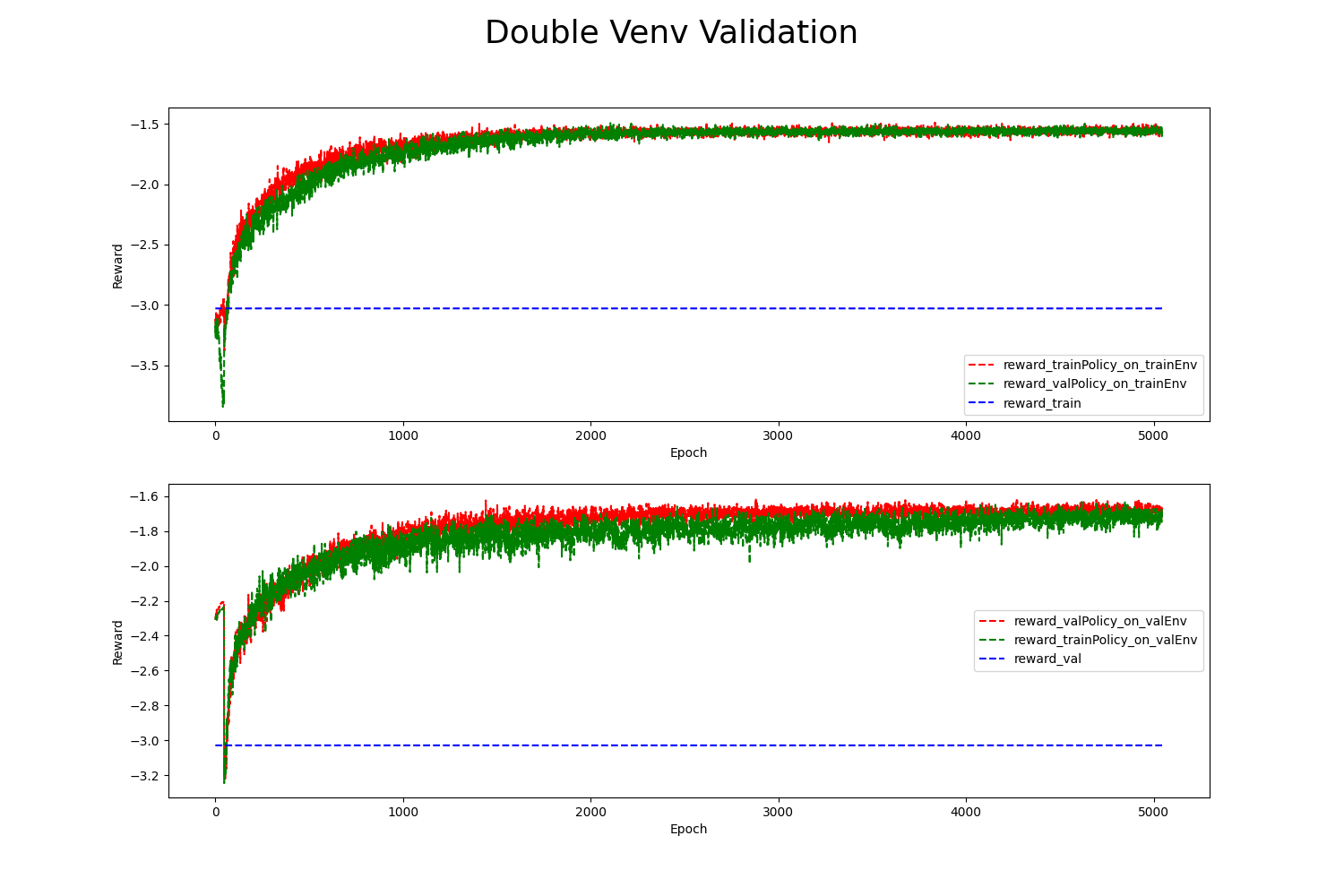
In the figure:
reward_val/reward_train: The blue dashed line represents the average single-step rewards calculated using the training/validation data in the user-defined reward function.
reward_*Policy_on_*Env: The red/green dashed lines represent the average single-step rewards recorded using the
*Policypolicy in the*Envvirtual environment.The upper and lower graphs show the results of the two policies in the
trainEnvandvalEnv, respectively.
From the graph, we can observe the following:
Both the red and green lines are higher than the blue dashed line, indicating that the rewards obtained by both policies in the two environments are higher than those in the historical dataset.
The red line in the upper graph (
reward_trainPolicy_on_trainEnv) and the green line in the lower graph (reward_trainPolicy_on_valEnv) exhibit similar trends as the training iterations increase. We can also observe the same trend from the green line in the upper graph and the red line in the lower graph. This suggests that the trainedtrainPolicydoes not overfit on its corresponding training virtual environmenttrainEnv. The resulting policy model can generalize to other environments.Since
trainPolicyperforms well invalEnv, we can infer that there is some similarity betweentrainEnvandvalEnv. This indicates that the hyperparameter settings during virtual environment training can produce similar and valuable environmental models on the partitioned training and validation data.
The graph below shows an example of a failed Double environment validation result.
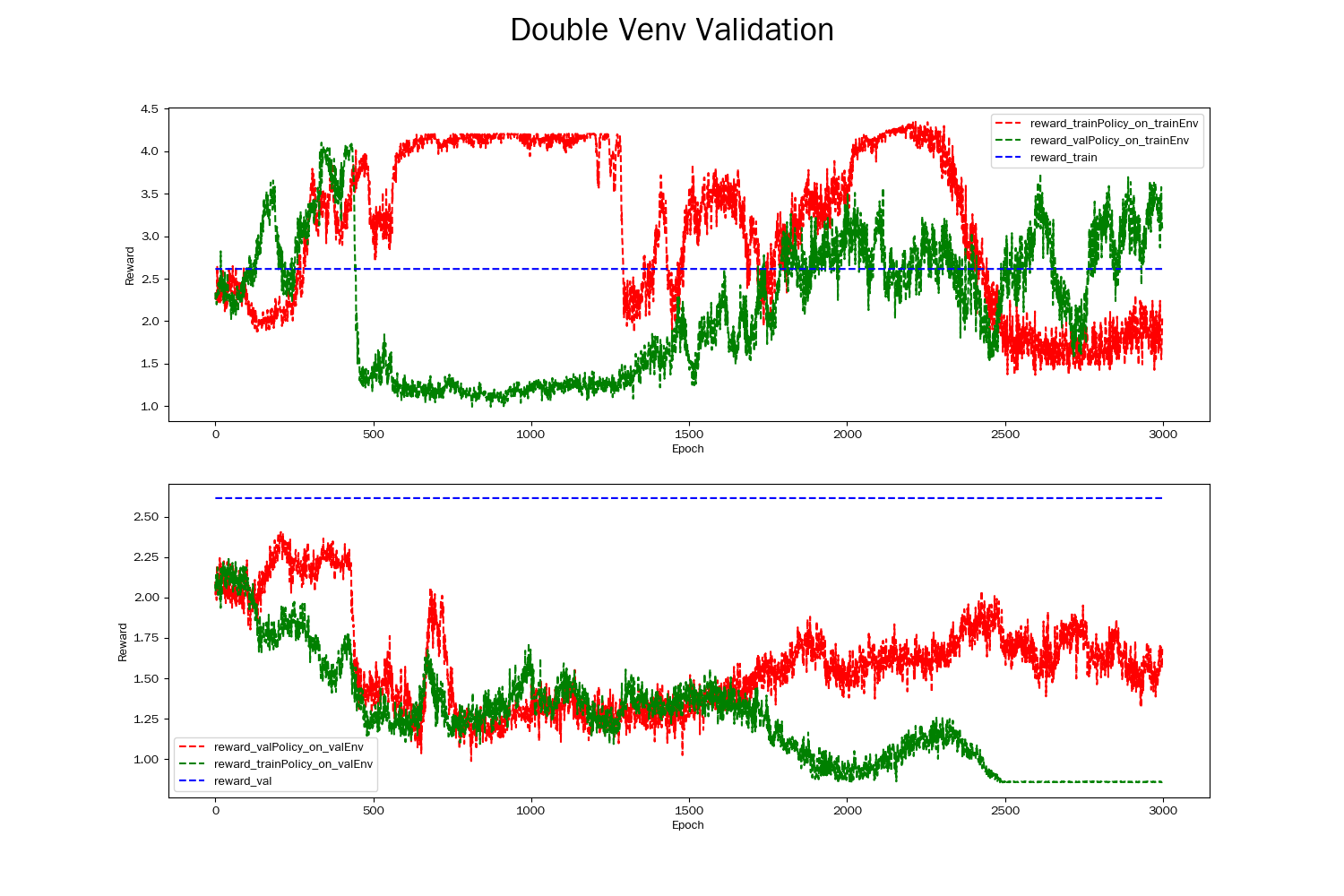
From the graph, we can observe that the same policy does not exhibit similar performance in the two environments. Additionally, both policies fail to converge stably and perform above the blue dashed line.
Generally, the reasons for a failed double environment validation are as follows:
Inconsistent training and testing environments. If there are significant differences in the data distribution of certain dimensions between the training and testing datasets, the performance of
trainPolicyonvalEnvmay be greatly compromised.Overfitting. When
trainPolicylearns excessive noise or patterns specific to a particular environment during training, it may perform poorly onvalEnv. IftrainPolicyhas a high complexity, it may overfittrainData, resulting in decreased performance invalEnv.Insufficient sample size. If the training data is too small, the model may not fully learn the patterns in the environment, leading to poor simulation of the real environment by the learned virtual environment.
Improper hyperparameter selection. For example, using a learning rate that is too high or too low, choosing an inappropriate discount factor, etc., can result in poor performance in the testing environment.
Dynamic environment changes. If the environment is highly dynamic, such as changes occurring during the training period, the model’s performance in the testing environment may differ.
Finally, it is important to note that double environment validation is one of many methods used to evaluate the performance of policy models and is an important indicator of their generalization performance. However, passing double environment validation does not guarantee ideal performance of the policy model in the actual real-world environment. It also does not imply that the learned virtual environment can perfectly replicate the real environment.